This chapter is from the book
This chapter is from the book
This chapter is from the book
Comparing Architecture Designs
Successful applications hosted at AWS have some semblance of high availability and/or fault tolerance in the underlying design. As you prepare for the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand these concepts conceptually in conjunction with the services that can provide a higher level of redundancy and availability. After all, if an application is designed to be highly available, it will have a higher level of redundancy; therefore, regardless of the potential failures that may happen from time to time, your application will continue to function at a working level without massive, unexpected downtime.
The same is true with a fault-tolerant design: If your application has tolerance for any operating issues such as latency, speed, and durability, your application design will be able to overcome most of these issues most of the time. The reality is that nothing is perfect, of course, but you can ensure high availability and fault tolerance for hosted applications by properly designing the application.
Designing for High Availability
Imagine that your initial foray into the AWS cloud involves hosting an application on a single large EC2 instance. This would be the simplest approach in terms of architecture, but there will eventually be issues with availability, such as the instance failing or needing to be taken down for maintenance. There are also design issues related to application state and data records stored on the same local instance.
As a first step, you could split the application into a web tier and a database tier with separate instances to provide some hardware redundancy; this improves availability because the two systems are unlikely to fail at the same time. If the mandate for this application is that it should be down for no more than 44 hours in any given 12-month period, this equates to 99.5% uptime. Say that tests show that the web server actually has 90% availability, and the database server has 95% reliability, as shown in Figure 3-1. Considering that the hardware, operating system, database engine, and network connectivity all have the same availability level, this design results in a total availability of 85.5%.
){kind=link}
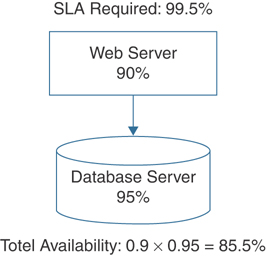
FIGURE 3-1 Availability Calculation for a Simple Hosted Application
This amount of uptime and availability obviously needs to be increased to meet the availability mandate. Adding an additional web server to the design increases the overall availability to 94.5%, as shown in Figure 3-2.
)
FIGURE 3-2 Increasing Application Availability by Adding Compute
The design now has some additional fault tolerance for the web tier so that one server can fail, but the application will still be available. However, you also need to increase the database tier availability because, after all, it’s where the important data is stored. Adding to the existing database infrastructure by adding two replica database servers in addition to adding a third web server to the web server tier results in both tiers achieving a total availability figure of 99.8% and achieving the SLA goal, as shown in Figure 3-3.
)
FIGURE 3-3 Adding Availability to Both Tiers
Adding Fault Tolerance
You can apply the same availability principles just discussed to the AWS data centers that host the application tiers. To do so, you increase application availability and add fault tolerance by designing with multiple availability zones, as shown in Figure 3-4.
)
FIGURE 3-4 Hosting Across Multiple AZ’s to Increase Availability and Fault Tolerance
Remember that each AWS availability zone has at least one physical data center. AWS data centers are built for high-availability designs, are connected together with high-speed/low-latency links, and are located far enough away from each other that a single natural disaster won’t affect all of the data centers in each AWS region at the same time. Thanks to this design, your application has high availability, and because of the additional availability, the application has more tolerance for failures when they occur.
Removing Single Points of Failure
Eliminating as many single points of failure as possible in your application stack design will also greatly increase high availability and fault tolerance. A single point of failure can be defined as any component of your application stack that will cause the rest of your integrated application to fail if that particular individual component fails. Take some time to review Table 3-2, which discusses possible mitigation paths for single points of failure.
Table 3-2 Avoiding Single Points of Failure
Possible Single Point of Failures |
Mitigation Plan |
Reason |
|---|---|---|
On-premises DNS |
Route 53 DNS |
Anycast DNS services hosted across all AWS regions. Health checks and DNS failover. |
Third-party load balancer |
Elastic Load Balancing (ELB) services |
ELB instances form a massive regional server farm with EIP addresses for fast failover. |
Web/app server |
ELB/Auto Scaling for each tier |
Scale compute resources automatically up and down to meet demand. |
RDS database servers |
Redundant data nodes (primary/standby) |
Synchronized replication between primary and standby nodes provides two copies of updated data |
EBS data storage |
Snapshots and retention schedule |
Copy snapshots across regions adding additional redundancy. |
Authentication problem |
Redundant authentication nodes |
Multiple Active Directory domain controllers provide alternate authentication options. |
Data center failure |
Multiple availability zones |
Each region has multiple AZs providing high-availability and failover design options. |
Regional disaster |
Multi-region deployment with Route 53 |
Route 53 routing policy provides geo-redundancy for applications hosted across regions. |
AWS recommends that you use a load balancer to balance the load of requests between multiple servers and to increase overall availability and reliability. The servers themselves are physically located in separate availability zones targeted directly by the load balancer. However, a single load-balancing appliance could be a single point of failure; if the load balancer failed, there would be no access to the application. You could add a second load balancer, but doing so would make the design more complicated as failover to the redundant load balancer would require a DNS update for the client, and that would take some time. AWS gets around this problem through the use of elastic IP addresses that allow for rapid IP remapping, as shown in Figure 3-5. The elastic IP address is assigned to multiple load balancers, and if one load balancer is not available ,the elastic IP address attaches itself to another load balancer.
)
FIGURE 3-5 Using Elastic IP Addresses to Provide High Availability
You can think of the elastic IP address as being able to float between resources as required. This software component is the mainstay of providing high-availability infrastructure at AWS. You can read further details about elastic IP addresses in Chapter 8, “Networking Solutions for Workloads.”
Table 3-3 lists AWS services that can be improved with high availability, fault tolerance, and redundancy.
Table 3-3 Planning for High Availability, Fault Tolerance, and Redundancy
AWS Service |
High Availability |
Fault Tolerance |
Redundancy |
Multi-Region |
|---|---|---|---|---|
EC2 instance |
Additional instance |
Multiple availability zones |
Auto Scaling |
Route 53 health checks |
EBS volume |
Cluster design |
Snapshots |
AMI |
Copy AMI/snapshot |
Load balancer |
Multiple AZs |
Elastic IP addresses |
Server farm |
Route 53 geo proximity load balancing options |
Containers |
Elastic Container Service (ECS) |
Fargate management |
Application load balancer/Auto Scaling |
Regional service not multi-region |
RDS deployment |
Multiple AZs |
Synchronous replication |
Snapshots/backup EBS data volumes and transaction records |
Regional service not multi-region. |
Custom EC2 database |
Multiple AZs and replicas |
Asynchronous/Synchronous replication options |
Snapshots/backup EBS volumes |
Custom high-availability and failover designs across regions with Route 53 Traffic Policies |
Aurora (MySQL/PostgreSQL) |
Replication across 3 AZs |
Multiple writers |
Clustered shared storage VSAN |
Global database hosted and replicated across multiple AWS regions |
DynamoDB (NoSQL) |
Replication across 3 AZs |
Multiple writers |
Continuous backup to S3 |
Global table replicated across multiple AWS regions |
Route 53 |
Health checks |
Failover routing |
Multi-value answer routing |
Geolocation/geo proximity routing |
S3 bucket |
Same-region replication |
Built-in |
Built-in |
Cross-region replication |